Generar un email diario a partir de un feed RSS (Slashdot)
Llevo décadas, literalmente, siguiendo Slashdot. Es una de mis fuentes de noticias de revisión diaria obligada. Se puede seguir a través del feed RSS, pero el tráfico diario es alto y es fácil perder noticias si pasas un par de días desconectado, porque, por ejemplo, estás de vacaciones o de viaje. Afortunadamente, Slashdot proporciona la opción de recibir un único mensaje diario con la recopilación de noticias del día anterior. Esto es muy conveniente para leerlas cuando te va bien, no preocuparte de perder noticias y, además, poder archivarlas en tu sistema de correo para futuras búsquedas o referencias.
Todo fue bien hasta el 23 de septiembre de 2018. Ese día me dejaron de llegar los mensajes diarios de noticias sin ningún motivo aparente [1]. Curiosamente, sí me llegaban los emails de Slashdot sobre promociones y publicidad.
Revisé mi configuración antispam, por si acaso mi servidor de correo electrónico se estaba comiendo los mensajes, los logs del servidor, etc., sin éxito. Preguntar online y revisar foros para ver si alguien más tenía problemas fue infructuoso. Intentar ponerme en contacto con la gente de Slashdot fue imposible.
Slashdot, sencillamente, ya no me enviaba los mensajes.
Durante un tiempo aguanté leyendo el feed RSS de forma diaria, pero los fines de semana eran problemáticos porque tenía apagado el ordenador un par de días y algunas noticias ya no entraban en el último feed RSS. Los lunes tocaba revisar noticias a mano.
Tras pensarlo un poco y evaluar el coste/beneficio, decidí crear un programa simple y mínimo para reemplazar el email de noticias que me enviaba Slashdot a diario. El programa me costó una tarde de trabajo y ha estado funcionando desde entonces sin ningún tipo de problema.
| [1] |
Slashdot empezó a enviarme las noticias diarias de nuevo el 6 de abril de 2019. Así, sin más. ¿Qué ocurrió? Imagino que nunca lo sabré. La cuestión es que ya tenía este reemplazo funcionando durante meses, sin publicidad, sin depender de terceros, sin comprometer mi privacidad... Sigo suscrito a las notificaciones diarias de Slashdot, pero ya ni siquiera abro esos emails. Tengo las mías y son mejores. |
El código completo es el siguiente:
slashdot-20181015.py (Código fuente)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 |
#!/usr/bin/env python3 # (c) 2018 Jesús Cea Avión - jcea@jcea.es - https://www.jcea.es/ # This code is licensed under AGPLv3. import os import time import subprocess import pickle from email.mime.text import MIMEText import email.utils import datetime import socket from bs4 import BeautifulSoup import feedparser path = 'items.pickle' class items: def __init__(self): self.cambiado = False with open(path, 'rb') as f: data = pickle.load(f) self._procesados = data['procesados'] self._buckets = data['buckets'] self._procesados_nuevos = set() self.etag = data['etag'] self.modified = data['modified'] self.saved = False def condicional(self): v = {} if self.etag: v['etag'] = self.etag if self.modified: v['modified'] = self.modified return v def solapamiento(self): if self.saved: return self._solapamiento return not self._procesados.isdisjoint(self._procesados_nuevos) def update(self, guid, ts, title, link, summary): self._procesados_nuevos.add(guid) bucket = (ts.tm_year, ts.tm_mon, ts.tm_mday) if bucket not in self._buckets: self._buckets[bucket] = {} if (ts, guid) in self._buckets[bucket]: return self._buckets[bucket][(ts, guid)] = (title, link, summary) self.cambiado = True def new(self, guid, ts, title, link, summary): if guid in self._procesados: self._procesados_nuevos.add(guid) return if guid in self._procesados_nuevos: return return self.update(guid, ts, title, link, summary) def itera_antiguos(self, horas=16): ts_antiguo = datetime.datetime.now() ts_antiguo -= datetime.timedelta(seconds=horas * 60 * 60) bucket_antiguo = (ts_antiguo.year, ts_antiguo.month, ts_antiguo.day) entradas = [] for bucket_name, bucket in self._buckets.items(): if bucket_name >= bucket_antiguo: continue for (ts, guid), (title, link, summary) in bucket.items(): entradas.append((ts, guid, title, link, summary)) for entrada in sorted(entradas, reverse=True): yield entrada def borrar(self, guid, ts): bucket = (ts.tm_year, ts.tm_mon, ts.tm_mday) del self._buckets[bucket][(ts, guid)] if not self._buckets[bucket]: del self._buckets[bucket] self.cambiado = True def save(self, etag, modified, purga=True): # XXX: Esto es necesario para que se guarden las cabeceras # de peticiones condicionales AUNQUE no haya habido cambios # en el propio feed. Algo a mejorar en el futuro, por ejemplo # pudiendo grabar solo eso. if (etag != self.etag) or (modified != self.modified): self.cambiado = True if not self.cambiado: return procesados = self._procesados_nuevos if not purga: procesados.update(self._procesados) with open(path + '.NEW', 'wb') as f: data = {'procesados': procesados, 'buckets': self._buckets, 'etag': etag, 'modified': modified, } pickle.dump(data, f, pickle.HIGHEST_PROTOCOL) f.flush() os.fsync(f.fileno()) os.rename(path + '.NEW', path) self.cambiado = False # Tras el save no deberíamos usar más este objeto self._solapamiento = self.solapamiento() self.saved = True del self._procesados del self._procesados_nuevos def main(): entradas = items() condicional = entradas.condicional() # XXX: Este timeout no es problema porque no tenemos múltiples hilos. # Habría que usar mejor "request" o similar. timeout = socket.getdefaulttimeout() socket.setdefaulttimeout(10) try: feed = feedparser.parse( 'http://rss.slashdot.org/Slashdot/slashdotMain', **condicional) finally: socket.setdefaulttimeout(timeout) if feed.status == 304: # print("Sin cambios") return for entry in feed.entries: summary = BeautifulSoup(entry["summary"], 'html.parser') summary = list(summary.children)[0] entradas.new(entry['id'], entry.updated_parsed, entry['title'], entry['link'], summary) no_solapamiento = '' if not entradas.solapamiento(): no_solapamiento = '<font size=+2><b>HEMOS PERDIDO ENTRADAS</b></font>' no_solapamiento += '<br/><br/>\n' html_desc = html_links = '' entradas_a_borrar = [] for ts, guid, title, link, summary in entradas.itera_antiguos(): link = f'<a href="{link}">{title}</a>' html_links += f'<li>{link}</li>\n' html_desc += (f'<b>{link}</b></br>\n<font size=-2>\n' f'{summary}\n</font></p>') entradas_a_borrar.append((guid, ts)) # XXX: Lo suyo sería grabar solo si hay cambios de verdad, pero # lo cierto es que queremos actualizar el etag y el modified AUNQUE # no haya habido cambios en el feed. Esto es algo a mejorar en el futuro. entradas.save(feed.get('etag'), feed.get('modified')) if html_desc: html_links = f'<ul>\n{html_links}\n</ul>\n' html = f'''<html> <head> <style> a {{text-decoration: none;}} </style> </head> <body> {no_solapamiento} {html_links} {html_desc} </body> </html> ''' msg = MIMEText(html, 'html') fecha = f'{time.strftime("%Y-%m-%d", feed.updated_parsed)}' msg['Subject'] = f'Feed Slashdot {fecha}' msg['To'] = 'jcea@jcea.es' msg['Date'] = email.utils.formatdate() msg['List-Id'] = 'Notificaciones Slashdot' msg['Message-Id'] = email.utils.make_msgid(domain='P2Ppriv') msg = msg.as_bytes() subprocess.run(['mail', 'jcea@jcea.es'], input=msg, check=True, timeout=60, stdout=subprocess.PIPE, stderr=subprocess.PIPE) # XXX: Lo suyo sería grabar solo si hay cambios de verdad, pero # lo cierto es que queremos actualizar el etag y el modified AUNQUE # no haya habido cambios en el feed. Esto es algo a mejorar en el futuro. entradas = items() for guid, ts in entradas_a_borrar: entradas.borrar(guid, ts) entradas.save(feed.get('etag'), feed.get('modified'), purga=False) if __name__ == '__main__': main() |
Observa que la licencia de mi código es Affero General Public License v3. Por favor, respétala.
Repasemos el programa paso a paso:
slashdot-20181015.py (Código fuente)
Importamos los módulos que voy a utilizar. Nada fuera de lo común. Para procesar el feed RSS empleo la biblioteca feedparser y para extraer el texto del HTML uso la popular BeautifulSoup4.
slashdot-20181015.py (Código fuente)
path = 'items.pickle' |
Aquí indicamos dónde vamos a grabar los datos. Usamos pickle, lo que no suele ser buena idea para programas serios, pero más que suficiente para mis necesidades aquí.
Nota
Esta versión del programa considera que ya tenemos un fichero de estado grabado previamente que vamos actualizando en cada ejecución. No se muestra la creación del estado inicial.
La gestión de los elementos del feed RSS y el procesamiento histórico se realizan en una instancia de la clase items:
slashdot-20181015.py (Código fuente)
El constructor de la clase items carga en memoria el último estado conocido.
El siguiente método nos devuelve valores necesarios para poder hacer un petición HTTP condicional:
slashdot-20181015.py (Código fuente)
def condicional(self): v = {} if self.etag: v['etag'] = self.etag if self.modified: v['modified'] = self.modified return v |
El método solapamiento nos dice si la última revisión del feed RSS se solapa con procesamientos anteriores. Si es así, todo va bien. Simplemente procesaríamos los elementos nuevos.
Si no hay solapamiento, significará que hemos perdido entradas.
slashdot-20181015.py (Código fuente)
def solapamiento(self): if self.saved: return self._solapamiento return not self._procesados.isdisjoint(self._procesados_nuevos) |
El método new procesa una entrada del feed RSS:
slashdot-20181015.py (Código fuente)
Lo primero que hace new es tomar nota de si se trata de un nuevo elemento no visto antes o no. Si ya lo hemos procesado en una invocación anterior del programa, tomamos nota de ello. Si la entrada es nueva, llama al método update, que se encarga de registrar la entrada en el cajón del día correcto. Es decir, cada noticia se almacena en un cajón que se corresponde a su día de publicación. Si el cajón no existe, lo crea primero. Si no hemos visto la entrada antes, la mete en el cajón correcto y marca la instancia del objeto como cambiado.
Las cosas se empiezan a poner interesantes en el método itera_antiguos:
slashdot-20181015.py (Código fuente)
Este método es un iterador que nos va entregando las noticias que han ocurrido en días anteriores a 16 horas (valor que se proporciona como parámetro por defecto, lo puedes cambiar) del momento actual. Es decir, a partir de las cuatro de la tarde, nos daría las noticias recibidas el día anterior y días previos. Esas noticias se entregarán en orden inverso, las más recientes primero.
La lógica de todo esto es que no me interesa recibir a las 12 de la noche noticias publicadas cinco minutos antes. Uno de los valores más distintivos e interesantes de Slashdot son los comentarios de la gente. Suelen ser mucho más valiosos que la propia noticia en sí. Me interesa, por tanto, recibir las noticias con cierto retraso para darles tiempo a acumular comentarios. En mi caso, el programa que he escrito me notifica solo las noticias que tienen al menos 16 horas de antigüedad y que no han sido publicadas hoy. Es decir, si ejecuto el programa a las once de la noche, no quiero que me envíe las noticias de hoy, sino las de ayer.
Esta consideración guio el diseño del programa entero: quiero recibir noticias con retraso, del día anterior al menos, y debe gestionar correctamente un volumen de noticias diario alto, detectando si hemos perdido alguna por no ejecutar el programa con la suficiente frecuencia.
Obsérvese también que el programa va añadiendo las noticias a los cajones correspondientes. Eso implica que puede mantener noticias atrasadas como pendientes de envío de forma indefinida si, por ejemplo, tenemos problemas con el sistema de correo. Al corregirlos saldrán todas las noticias atrasadas, aunque lleven semanas retenidas. No perdemos nunca nada.
El uso del método borrar es bastante evidente:
slashdot-20181015.py (Código fuente)
def borrar(self, guid, ts): bucket = (ts.tm_year, ts.tm_mon, ts.tm_mday) del self._buckets[bucket][(ts, guid)] if not self._buckets[bucket]: del self._buckets[bucket] self.cambiado = True |
El método borra las noticias que se le indiquen de su cajón correspondiente y si dicho cajón está vacío, borramos el cajón en sí. Si ha habido cambios, marcamos el objeto como cambiado.
Por último, el método save se encarga de almacenar el estado en el disco duro como pickle:
slashdot-20181015.py (Código fuente)
El método recibe como parámetros datos útiles para poder hacer peticiones HTTP condicionales. Si los datos son diferentes a los que teníamos ya, forzamos un volcado aunque no haya cambiado nada más (líneas 96-97).
Si no hay necesidad de grabar nada, no lo hacemos (línea 99-100).
Si hay motivos para grabar el estado, podemos hacer limpieza o no de noticias que ya han desaparecido del feed RSS. Si están en un cajón, pendientes de envío, se mantendrán ahí. El borrado afecta simplemente al control de duplicados y a la detección de que hemos perdido noticias.
A continuación grabamos el estado en un fichero temporal como pickle, nos aseguramos de que está grabado realmente en el disco (líneas 111-113) y reemplazamos el fichero de estado original (línea 114). Esto es un patrón clásico en el mundo Unix. No quiero sobreescribir el estado directamente porque un error de grabación, un corte de luz, etc., dejaría el estado corrupto. Hay que asegurarse de que el estado nuevo se ha grabado correctamente a disco antes de reemplazar el viejo. En Unix el renombrado de ficheros se garantiza como atómico [2]:
| [2] |
Siempre que se realice dentro de una misma unidad de almacenamiento. Renombrar un fichero entre unidades de almacenamiento distintas supone una copia seguida de un borrado, y la operación conjunta no es atómica. El manual de Linux dice lo siguiente:
Te puede interesar echar un vistazo al artículo Things UNIX can do atomically. |
El último paso del método es invalidar el objeto. Una instancia cuyo estado se ha volcado a disco no debe ser utilizada de nuevo, debe recrearse una instancia nueva a partir de dicho estado.
Lo he hecho así por sencillez y porque mi programa simplemente termina al finalizar el procesado del feed RSS. No es un demonio funcionando permanentemente.
El programa en sí se ejecuta en la función main:
slashdot-20181015.py (Código fuente)
El primer lugar creamos una instancia de la clave items, lo que cargará el estado previo almacenado en disco (línea 125). A continuación se obtiene la información necesaria para poder realizar una petición HTTP condicional (línea 127).
Las líneas 131-132 y 137 configuran un tiempo límite para las conexiones TCP. Como se explica en el comentario (líneas 129-130), la configuración es un poco basta, pero suficiente para nuestras necesidades.
Obtenemos el feed RSS en las líneas 134-135 mediante una conexión HTTP condicional. Si el feed RSS no ha cambiado, hemos terminado (líneas 139-141).
slashdot-20181015.py (Código fuente)
Este trozo de código repasa en feed RSS y añade las entradas a la instancia de items. Ya hemos descrito el código más arriba, en particular la gestión que se hace según se haya visto antes o no cada noticia.
slashdot-20181015.py (Código fuente)
Aquí repasamos las noticias pendientes de envío y vamos recopilando títulos, enlaces y resúmenes. Se toma nota de las noticias que vamos a enviar por correo para poder borrarlas al final si el envío ha tenido éxito.
En la línea 167 grabamos el estado actual de la instancia items. La idea es que no perdamos las noticias pendientes si el envío de email falla. Cuando se solucione el problema con el correo, saldrá todo lo pendiente de una vez.
slashdot-20181015.py (Código fuente)
Si tenemos algo que enviar (línea 169), construimos el email y lo enviamos. Obsérvese la construcción de las cabeceras (líneas 187-191), especialmente las cabeceras List-Id (línea 190) y Message-ID (línea 191).
Para enviar el mensaje se usa el comando mail, estándar en Unix. No es la forma más eficiente, pero es simple y nos basta. Nos protegemos de cuelgues o problemas de funcionamiento especificando un tiempo máximo de espera. El destino está cableado; naturalmente, tú tendrás que usar otro email.
Si el envío falla, el programa se corta. En la siguiente ejecución se volverá a cargar el estado, se actualizará con las noticias nuevas que haya en el feed RSS, veremos que hay noticias pendientes de ser enviadas y se volverá a intentar la entrega del correo electrónico. El proceso se repetirá las veces que sea preciso, hasta que se pueda enviar el email. Ni que decir tiene que lo habitual es que el correo se pueda enviar a la primera.
Si el correo se encola correctamente, pasamos a la última parte del proceso:
slashdot-20181015.py (Código fuente)
Si todo ha ido bien, volvemos a cargar el estado (línea 202). Recordemos que la implementación actual del objeto no permite seguir utilizándolo tras haber hecho save() en la línea 167, así que necesitamos una instancia nueva. A continuación eliminamos las noticias que acabamos de enviar por correo electrónico y volvemos a grabar el estado actualizado (línea 206). En esta ocasión le pasamos el parámetro purga=False porque esta nueva instancia no ha recibido un feed RSS nuevo y no queremos que haga limpieza, ya lo ha hecho en la línea 167. Si lo volvemos a hacer, tendremos noticias duplicadas y avisos espurios de que hemos perdido noticias.
slashdot-20181015.py (Código fuente)
if __name__ == '__main__': main() |
El fragmento final es típico de un programa en Python.
¿Cómo queda la cosa? Aquí pongo un par de capturas:
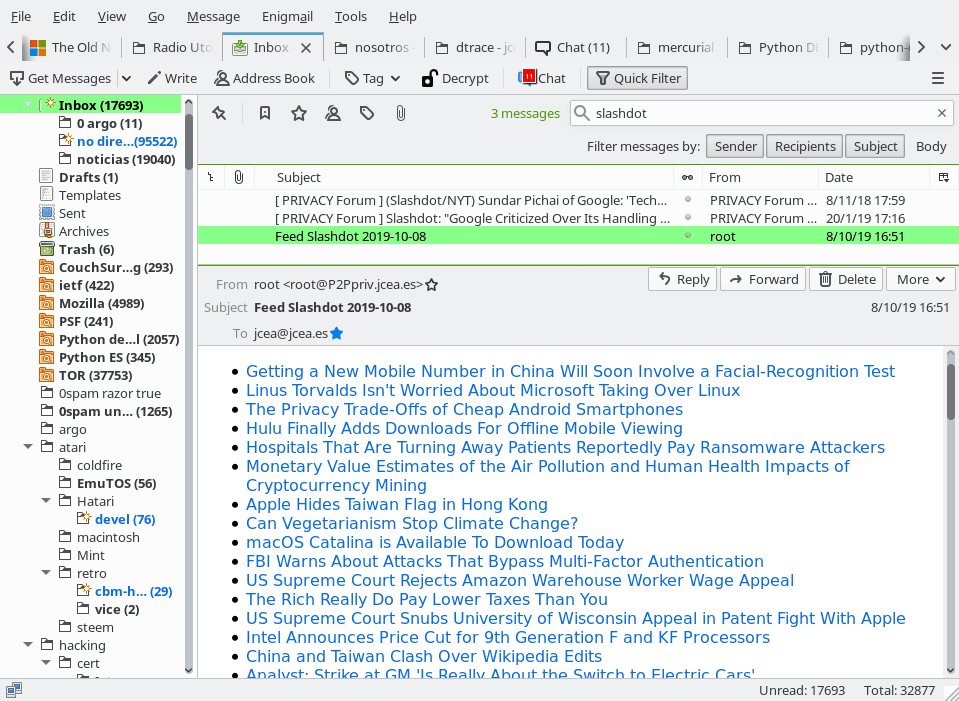
En la foto de arriba vemos mi cliente de correo (Mozilla Thunderbird) mostrando algunos de los titulares del día.
En la foto de abajo hemos avanzado en el mensaje de correo electrónico y vemos que tras los titulares se incluye un pequeño resumen de cada noticia:
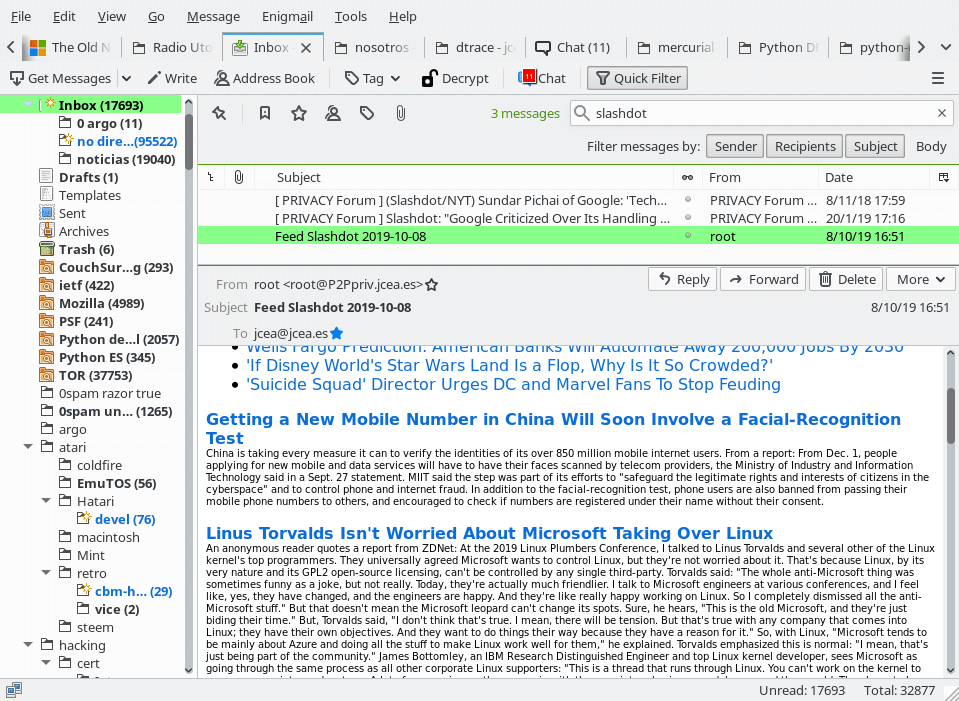
Bien... ¿y cómo ejecutamos todo esto?
Este código se ejecuta en uno de mis servidores, cada hora, mediante cron. La máquina está funcionando 24x7 salvo actualizaciones y similares.
La frecuencia de ejecución no es crítica, aunque debe ser lo bastante frecuente como para que una noticia no desaparezca del feed RSS antes de que hayamos tenido la ocasión de capturarla. Slashdot tiene soporte de peticiones HTTP condicionales y mi programa lo utiliza, así que una ejecución muy frecuente tampoco debería ser problemática ni para nosotros ni para Slashdot. Si lo ejecutas cada hora, como yo, elige un minuto al azar. No lo lances exactamente a la hora en punto. Por cortesía, vaya.
El programa no genera ninguna salida por stdout o stderr, así que el cron no debería molestarnos con avisos de correo a menos que el programa esté fallando. En ese caso, claro que queremos que nos moleste :-).
Cosas a mejorar
El programa lleva funcionando un año sin ningún tipo de incidencia, pero solo he hecho lo mínimo imprescindible para salir del paso con mi problema con Slashdot. No ha sido mi intención hacer algo general para que lo pueda usar cualquiera simplemente cambiando un fichero de configuración.
El código también tiene fragmentos legacy que convendría limpiar.
-
Que no podamos seguir utilizando una instancia items tras haber ejecutado su método save() tiene motivos históricos, pero ahora mismo nos perjudica. Complica el código de forma innecesaria.
Hay más complicaciones históricas que ya no son necesarias. Por ejemplo, podemos actualizar el estado en disco siempre, no de forma selectiva.
-
Es posible que el email de noticias diarias se retrase hasta que el feed RSS tenga alguna modificación. Con Slashdot no hay problema porque el feed RSS tiene bastante actividad.
-
El envío del email diario debería hacerse en una función separada, pasando los parámetros como un SimpleNamespace o similar.
-
No hay código que evite la ejecución de varias instancias simultáneas.
-
El envío de correo podría ser una conexión directa a un servidor SMTP, en vez de usar el comando mail. Esto sería compatible con otros sistemas operativos, a costa de más configuración y detalles delicados como usuarios y claves de acceso.
Actualización 20200330: Continúa leyendo en Mejoras a la hora de generar un email diario a partir de un feed RSS (Slashdot).