Detección y diagnóstico de pérdida de datos en LizardFS
Advertencia
La instalación LizardFS que describo de pasada en este documento es un compendio de malas prácticas de libro. Por favor, no utilices nada que se parezca a esta topología en tu instalación LizardFS.
Como consecuencia evidente, no interpretes este documento como que LizardFS es un mal sistema de ficheros proclive a la pérdida de datos. LizardFS tiene muchos problemas técnicos y culturales, pero este artículo no trata sobre ellos.
Personalmente, he intentado mejorar la configuración de esa instalación LizardFS, pero la resistencia de su propietario ha sido inamovible... incluso tras esta pérdida de datos.
Hace unas semanas una instalación LizardFS que ayudo a administrar perdió un servidor completo con cinco discos duros. La red LizardFS constaba de treinta discos duros repartidos en media docena de máquinas. Los ficheros se almacenaban de forma redundante siguiendo dos políticas diferentes:
-
Espejo: Cada fichero se almacena en dos o tres discos duros diferentes. En esta instalación LizardFS, lamentablemente, no hay reglas que prohíban que todas las copias residan en un mismo servidor (en diferentes discos duros conectados a un mismo servidor).
Es decir, podríamos tener la mala suerte de que todas las copias residan en el mismo servidor y si perdemos el servidor entero (fallo hardware, reinicio, etc), pues tendremos datos inaccesibles porque nos desaparecen varios discos duros a la vez.
La solucion evidente es configurar LizardFS para que considere todos los discos duros de un mismo servidor como pertenecientes a una misma zona de fallo y evite reutilizar una misma zona de fallo para almacenar las diferentes copias de redundancia.
-
Corrección de errores 8+2: El modo espejo es simple de entender y operar, y resulta también ventajoso en rendimiento a la hora de leer datos. Su problema más evidente es el consumo de recursos: los datos ocupan el doble o el triple de lo necesario.
Para la mayor parte de los datos almacenados en esta instalación LizardFS utilizo un esquema de redundancia 8+2. Esto significa lo siguiente:
-
Cada fichero almacenado se divide en ocho fragmentos [1].
-
Utilizando técnicas de detección y corrección de errores, se procesan esos ocho fragmentos y se generan dos fragmentos adicionales sintéticos [1].
-
Esos diez fragmentos en total (los ocho originales más los dos fragmentos de redundancia) se almacenan en diferentes discos duros [1].
Esto implica que un fichero de 8 megabytes ocupa realmente 10 megabytes en LizardFS. Esto supone una sobrecarga de espacio del 25% en vez del 100% de sobrecarga que requiere un espejo. Además, el espejo proporciona menos resistencia, porque podemos perder información si nos desaparecen dos discos duros concretos, mientras que con ec82 podemos perder dos discos duros cualesquiera sin que nos cause problemas.
-
Cuando leemos los datos, podemos recuperar la información original si somos capaces de leer ocho fragmentos cualesquiera de los diez fragmentos almacenados (ocho de datos y dos de redundancia).
Es decir, podemos perder dos discos duros cualesquiera sin perder datos.
Lamentablemente, no se ha usado información topológica en esta instalación LizardFS. Aunque cada fragmento se almacena en un disco duro diferente, no hay nada que impida que haya tres o más fragmentos en discos duros conectados a un mismo servidor. Si perdemos un servidor, podríamos perder más de dos fragmentos [1] dejando el fichero inaccesible.
-
| [1] |
(1, 2, 3, 4, 5) Cuando digo que LizardFS divide un fichero en dos fragmentos y a partir de ellos genera uno nuevo de redundancia, estoy simplificando. En realidad, LizardFS divide previamente los ficheros en trozos de 64 Megabytes (valor por defecto, configurable) y son esos trozos los que se replican, los que se protegen con redundancia, etc. Esto tiene ventajas sobre sistemas de ficheros como Ceph, que maneja ficheros como unidades atómicas y se producen desequilibrios muy problemáticos si tenemos ficheros o discos duros con tamaños muy diferentes. Algún día escribiré sobre mis experiencias con Ceph. |
¿Qué ocurre cuando LizardFS no puede reconstruir un fichero?
LizardFS tiene dos interfaces de administración: una interfaz por línea de comandos y una interfaz web.
Aquí vemos la página principal de la interfaz web mostrando una visión global del sistema. Abajo nos salen los primeros 500 ficheros irrecuperables:
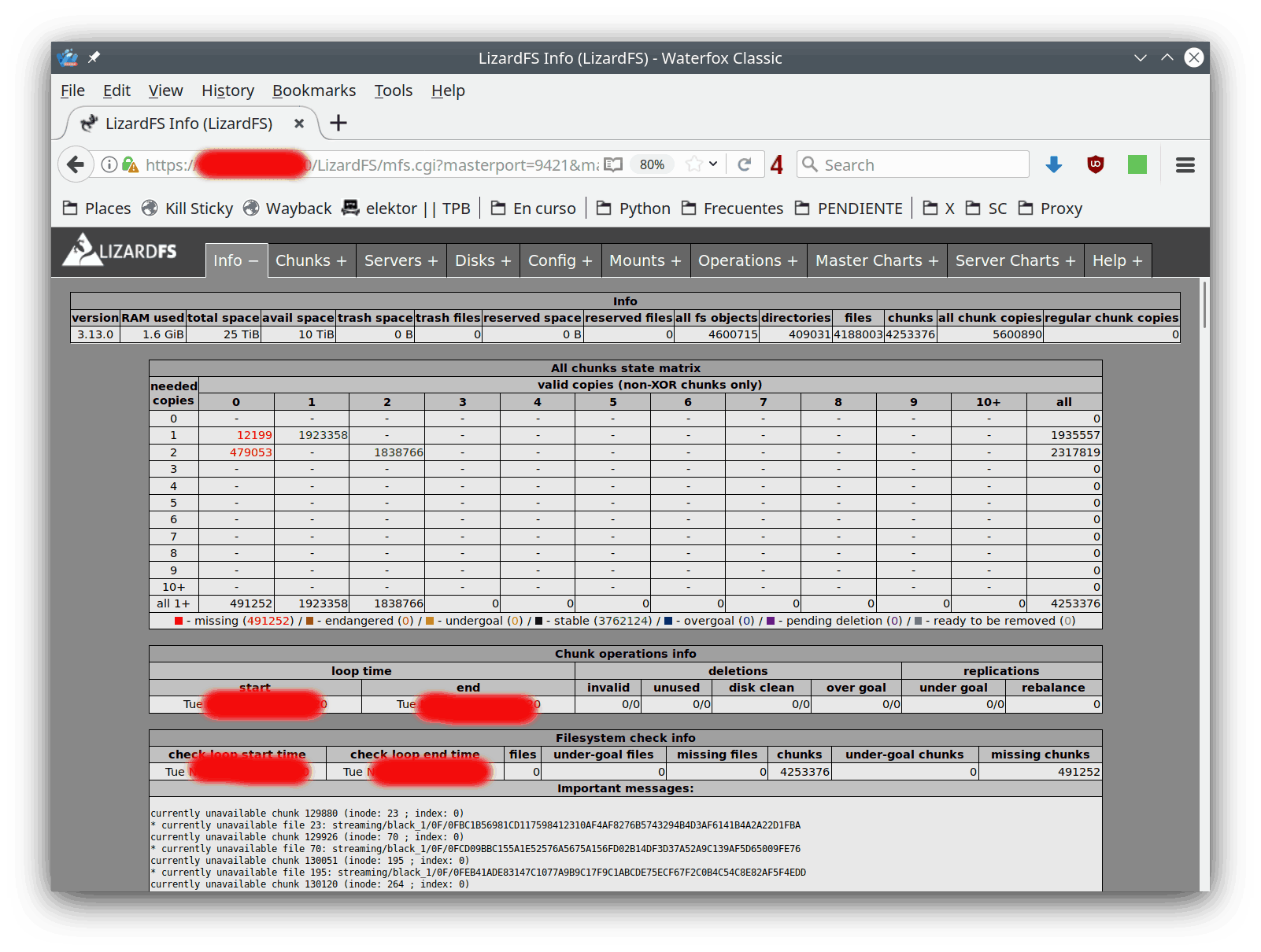
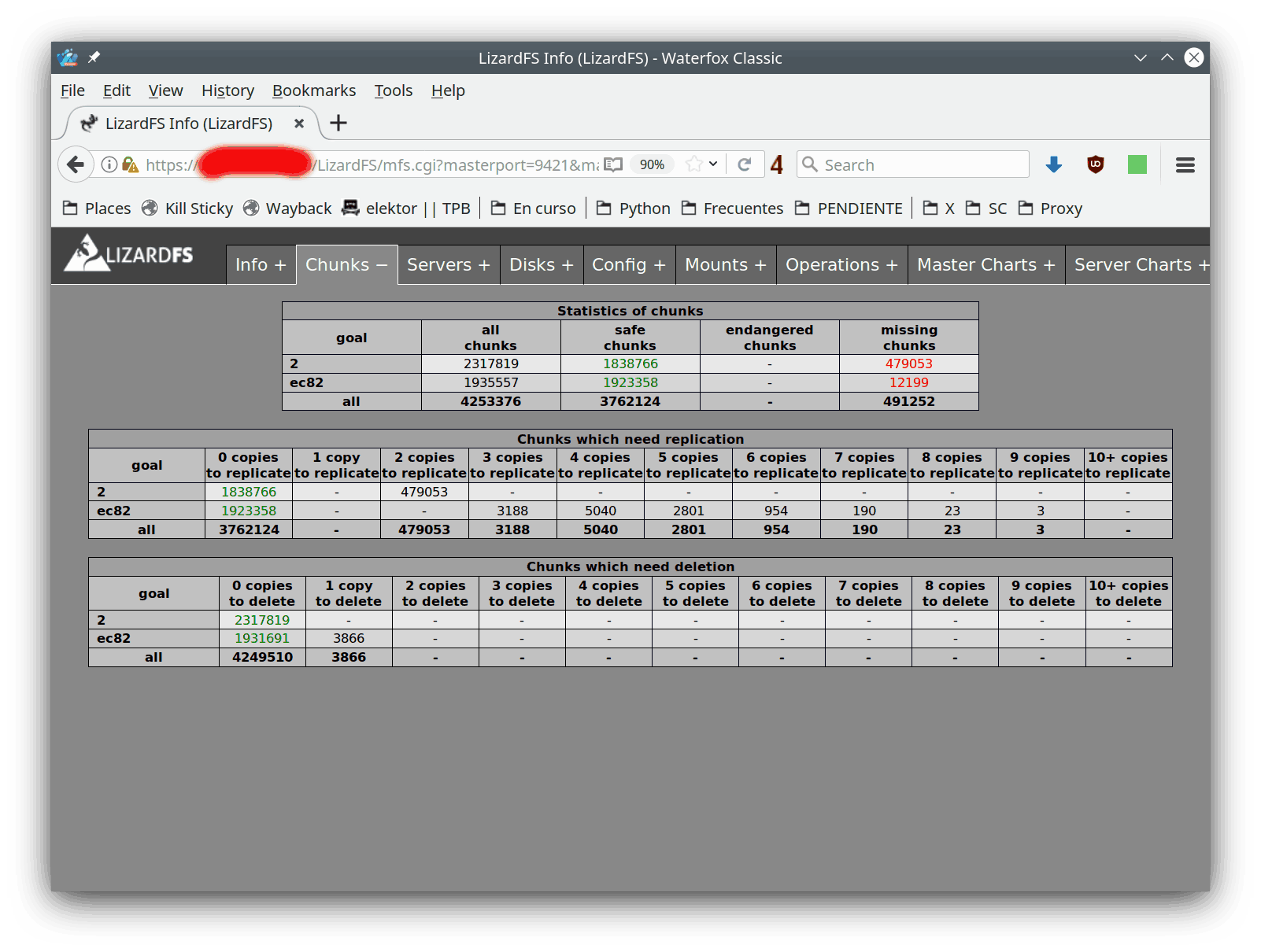
En esta pestaña vemos la distribución de errores. El objetivo "2" es un espejo, mientras que "ec82" se refiere al esquema 8+2 descrito más arriba:
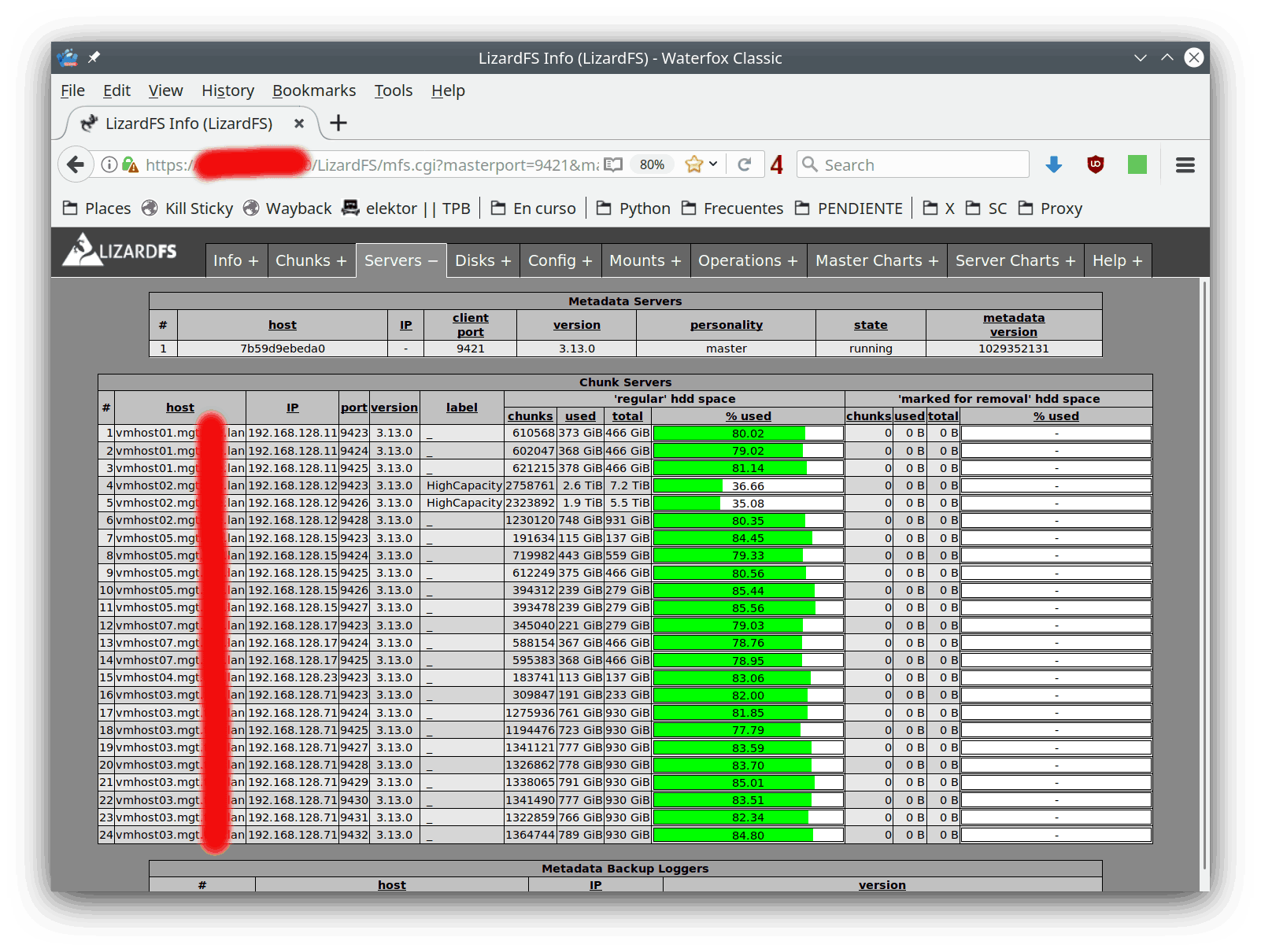
Aquí tenemos la distribución de discos duros y podemos ver en qué servidores está cada uno de ellos:
La interfaz de línea de comandos de LizardFS permite obtener fácilmente el listado de ficheros irrecuperables:
root@dmzjcea:/home/jcea# lizardfs-admin list-defective-files \ --unavailable --limit=9999999 \ 192.168.128.106 9421 Files with error flag = unavailable file 23: jcea/black_1/0F/0FBC1B56981CD117598412310AF4AF8276B5743294B4D3AF6141B4A2A22D1FBA - unavailable file 70: jcea/black_1/0F/0FCD09BBC155A1E52576A5675A156FD02B14DF3D37A52A9C139AF5D65009FE76 - unavailable file 195: jcea/black_1/0F/0FEB41ADE83147C1077A9B9C17F9C1ABCDE75ECF67F2C0B4C54C8E82AF5F4EDD - unavailable [...]
Aquí obtenemos la lista de ficheros irrecuperables. Es importante poner un límite explícito en cuántos ficheros mostrar, ya que por defecto solo se listarán mil ficheros y a nosotros nos están fallando bastantes más.
Podemos ver los detalles de un fichero determinado:
root@dmzjcea:/srv/datos# lizardfs fileinfo jcea/black_1/0F/0FBC1B56981CD117598412310AF4AF8276B5743294B4D3AF6141B4A2A22D1FBA jcea/black_1/0F/0FBC1B56981CD117598412310AF4AF8276B5743294B4D3AF6141B4A2A22D1FBA: chunk 0: 000000000001FB58_00000002 / (id:129880 ver:2) copy 1: 192.168.128.11:9424:_ part 2/10 of ec(8,2) copy 2: 192.168.128.12:9423:HighCapacity part 1/10 of ec(8,2) copy 3: 192.168.128.12:9426:HighCapacity part 6/10 of ec(8,2) copy 4: 192.168.128.15:9424:_ part 5/10 of ec(8,2) copy 5: 192.168.128.15:9425:_ part 8/10 of ec(8,2) copy 6: 192.168.128.71:9424:_ part 7/10 of ec(8,2) not enough parts available
Aquí podemos ver el estado de los diez fragmentos que se almacenan con el objetivo ec82. Vemos que solo están disponibles seis de los ocho fragmentos necesarios para recuperar la información. Mala suerte (bueno, en realidad el problema no es la suerte, sino la mala configuración de este almacenamiento LizardFS en particular). Solo queda borrar esos ficheros y recuperarlos de la copia de seguridad.
Veamos un fichero correcto, sin pérdida de datos:
root@dmzjcea:/srv/datos/jcea# lizardfs fileinfo z-a_borrar.txt z-a_borrar.txt: chunk 0: 00000000006F6C98_00000001 / (id:7302296 ver:1) copy 1: 192.168.128.15:9423:_ part 4/10 of ec(8,2) copy 2: 192.168.128.15:9425:_ part 1/10 of ec(8,2) copy 3: 192.168.128.15:9426:_ part 8/10 of ec(8,2) copy 4: 192.168.128.15:9427:_ part 3/10 of ec(8,2) copy 5: 192.168.128.17:9423:_ part 5/10 of ec(8,2) copy 6: 192.168.128.23:9423:_ part 10/10 of ec(8,2) copy 7: 192.168.128.71:9423:_ part 7/10 of ec(8,2) copy 8: 192.168.128.71:9428:_ part 6/10 of ec(8,2) copy 9: 192.168.128.71:9431:_ part 9/10 of ec(8,2) copy 10: 192.168.128.71:9432:_ part 2/10 of ec(8,2)
¿Qué pasa si intentamos leer un fichero ilegible?
root@dmzjcea:/srv/datos# time cat jcea/black_1/0F/0FBC1B56981CD117598412310AF4AF8276B5743294B4D3AF6141B4A2A22D1FBA >/dev/null cat: jcea/black_1/0F/0FBC1B56981CD117598412310AF4AF8276B5743294B4D3AF6141B4A2A22D1FBA: Input/output error real 5m2.803s user 0m0.000s sys 0m0.000s
Por defecto (esto es configurable), LizardFS dará un error de lectura tras intentar leer el fichero durante cinco minutos.
¿Qué error exacto se produce? Veámoslo en Python:
>>> import errno >>> try: ... open("jcea/black_1/0F/0FBC1B56981CD117598412310AF4AF8276B5743294B4D3AF6141B4A2A22D1FBA").read() ... except Exception as e: ... exc = e ... >>> exc.errno == errno.EIO True
La descripción de ese error es:
EIO I/O error. This will happen for example when the process is in a background process group, tries to read from its controlling terminal, and either it is ignoring or blocking SIGTTIN or its process group is orphaned. It may also occur when there is a low-level I/O error while reading from a disk or tape. A further possible cause of EIO on networked filesystems is when an advisory lock had been taken out on the file descriptor and this lock has been lost. See the Lost locks section of fcntl(2) for further details.
Básicamente, LizardFS está simulando un error de lectura de bajo nivel, como si un sector de un disco duro estuviese corrupto de forma irrecuperable. Semánticamente este error es el más apropiado y otros sistemas de ficheros como NFS (en el modo soft mount) optan por mostrar el mismo error si no son capaces de entregarte la información solicitada.
¿Cómo limpiar de errores un almacenamiento LizardFS?
Lo ideal sería volver a reconectar los discos duros desaparecidos. No es necesario que estén en el mismo servidor antiguo o, incluso, que estén todos enchufados en la misma máquina. Si LizardFS encuentra los fragmentos desaparecidos, los utilizará; le da igual cómo ha llegado a ellos.
Puede ser que el servidor sea irrecuperable y que los demás servidores tengan los puertos de disco duro completos. En ese caso se podría hacer algo similar a lo siguiente:
-
Enchufamos uno de los discos duros desaparecidos por USB, por ejemplo, y configuramos LizardFS para darle visibilidad.
Por muy llenos que estén los servidores, seguro que podemos enchufarles algún disco por USB de forma temporal. En el peor de los casos, hasta podríamos usar una Raspberry PI durante unas horas para esta tarea.
-
En cuanto LizardFS vea alguno de los discos duros que habían desaparecido, podremos recuperar algunos de los ficheros (los que hayan pasado de tres fragmentos desaparecidos a solo dos). Pero, en vez de dedicarnos a recuperar los ficheros rescatados, que serán una minoría de todos los perdidos, es mejor proceder a la baja controlada de ese disco duro.
-
Para ello, configuramos LizardFS para reconocer que ese disco duro por USB se quiere retirar. Una vez activada esa función, LizardFS se dedicará a mover los datos de ese disco duro al resto del almacenamiento LizardFS. Este proceso puede llevar varias horas, dependiendo de la carga del almacenamiento, la velocidad USB, la velocidad de la red y el volumen de datos a mover.
-
Una vez que se ha vaciado ese disco duro (sus datos se habrán repartido por el resto del almacenamiento LizardFS), podemos desenchufarlo del USB. Enchufamos otro disco duro de los desaparecidos y repetimos desde el paso 3.
-
Cuando nos queden dos discos duros por vaciar, LizardFS verá que ya tiene al menos ocho fragmentos de datos (de los diez totales de una configuración 8+2) y ya se habrá dedicado a reconstruir ficheros y regenerar la redundancia. Si no hacemos nada más, LizardFS será capaz de recuperar todos los ficheros cuyo objetivo era ec82 y reconstruir de nuevo su redundancia 8+2.
-
Podemos seguir vaciando los dos discos duros desaparecidos que faltan, sin mayor problema. Técnicamente no sería necesario, pero si hay algún otro disco duro que está dando guerra, así nos aseguramos de recuperarlo todo.
Se generará redundancia redundante (valga la... ¡redundancia!), pero no pasa nada. LizardFS irá viendo que le sobra información para el objetivo de 8+2 e irá borrando fragmentos innecesarios por su cuenta. Basta con darle unas horas para que haga limpieza. Por supuesto, durante ese tiempo los datos almacenados en LizardFS estarán disponibles, simplemente habrá más espacio ocupado que el objetivo buscado. Ese espacio se irá liberando poco a poco, sin hacer nada especial.
-
Los ficheros con objetivo "espejo" que hayan tenido mala suerte y ambas copias estén en los dos discos duros perdidos que aun no hemos vaciado, seguirán inaccesibles. Habrá que enchufar y desalojar al menos uno de los discos duros que faltan. Cuando haya una copia de los datos disponible, LizardFS regenerará automáticamente la otra copia en otro disco duro para recuperar la redundancia en espejo.
-
Por todo lo anterior, aunque técnicamente no sea necesario, yo recomendaría evacuar todos los discos duros desaparecidos, si es posible. Saber qué es lo mínimo a evacuar depende de conocer los detalles de configuración de objetivos de los diferentes ficheros contenidos en LizardFS. Esto puede ser algo esotérico si no entiendes cómo se configuró LizardFS. Lo más sencillo sería evacuar todos los discos duros y que LizardFS se encargue tanto de reconstruir la redundancia cuando tiene información suficiente, como de destruir redundancia si está por encima de los objetivos de disponibilidad configurados. [2]
[2] Los objetivos de redundancia en LizardFS se pueden configurar de manera casi arbitraria y cada fichero del sistema de ficheros puede tener un objetivo diferente. Un fichero creado nuevo heredará los objetivos de redundancia de su directorio padre, pero su objetivo se puede cambiar en cualquier momento, tanto para subir como para reducir redundancia.
En este caso concreto, nada de esto es posible: El propietario de esta instalación LizardFS borró y reutilizó los discos duros para otros usos cuando falló el servidor en el que estaban alojados. No tuve ocasión de evacuar los datos antes del borrado de discos. En esas circunstancias no hay nada que yo o LizardFS podamos hacer más allá de borrar esos ficheros inaccesibles y recuperarlos de una copia de seguridad.
Para borrar esos ficheros hice algo similar a:
root@dmzjcea:/srv/datos# for i in `lizardfs-admin list-defective-files \ --unavailable --limit=9999999 192.168.128.106 9421 \ | tail +2 | grep ": jcea/" \ | cut -d " " -f 5`; \ do echo $i; \ rm "$i"; \ done
Este código lista los ficheros inaccesibles bajo el directorio jcea/, mi responsabilidad, y los va borrando uno a uno. Funciona correctamente porque sé que los nombres de mis ficheros bajo ese directorio no contienen espacios u otros caracteres considerados separadores. Si no pudiéramos garantizarlo, habría que complicar un poco el código. Yo no lo he necesitado.
En total borro 12.338 ficheros de un total de 1.935.696. He perdido un 0.637% de los ficheros, lo que no está mal tras haber perdido cinco discos duros de un total de treinta. Afortunadamente, esos discos eran relativamente pequeños comparados con los que quedaron, así que se llevaron por delante menos ficheros de lo que podría parecer.
Una vez que mi area LizardFS estuvo limpia, volví a subir a LizardFS los ficheros destruidos desde otras réplicas remotas, dejando todo como estaba. Tener esos datos disponibles en otros lugares no fue suerte, fue... experiencia :-).
Objetivos de redundancia de LizardFS
En LizardFS se pueden configurar hasta cuarenta objetivos de redundancia diferentes y cada fichero puede configurarse con cualquiera de ellos y cambiarse en cualquier momento. En esta instalación en concreto de LizardFS hemos configurado tres objetivos diferentes:
root@dmzjcea:/srv/datos# lizardfs-admin list-goals 192.168.128.106 9421 Goal definitions: Id Name Definition 1 1 1: $std _ 2 2 2: $std {HighCapacity _} 3 3 3: $std {_ _ _} 4 4 4: $std {_ _ _ _} 5 5 5: $std {_ _ _ _ _} 6 6 6: $std {_ _ _ _ _} 7 7 7: $std {_ _ _ _ _} 8 xor2h xor2h: $xor2 {HighCapacity _ _} 9 9 9: $std {_ _ _ _ _} 10 10 10: $std {_ _ _ _ _} 11 11 11: $std {_ _ _ _ _} 12 12 12: $std {_ _ _ _ _} 13 13 13: $std {_ _ _ _ _} 14 14 14: $std {_ _ _ _ _} 15 15 15: $std {_ _ _ _ _} 16 16 16: $std {_ _ _ _ _} 17 17 17: $std {_ _ _ _ _} 18 18 18: $std {_ _ _ _ _} 19 19 19: $std {_ _ _ _ _} 20 ec82 ec82: $ec(8,2) {_ _ _ _ _ _ _ _ _ _} 21 21 21: $std {_ _ _ _ _} 22 22 22: $std {_ _ _ _ _} 23 23 23: $std {_ _ _ _ _} 24 24 24: $std {_ _ _ _ _} 25 25 25: $std {_ _ _ _ _} 26 26 26: $std {_ _ _ _ _} 27 27 27: $std {_ _ _ _ _} 28 28 28: $std {_ _ _ _ _} 29 29 29: $std {_ _ _ _ _} 30 30 30: $std {_ _ _ _ _} 31 31 31: $std {_ _ _ _ _} 32 32 32: $std {_ _ _ _ _} 33 33 33: $std {_ _ _ _ _} 34 34 34: $std {_ _ _ _ _} 35 35 35: $std {_ _ _ _ _} 36 36 36: $std {_ _ _ _ _} 37 37 37: $std {_ _ _ _ _} 38 38 38: $std {_ _ _ _ _} 39 39 39: $std {_ _ _ _ _} 40 40 40: $std {_ _ _ _ _}
La primera columna es el identificador del objetivo y la segunda es su nombre. Los primeros cinco objetivos son espejos con diferentes números de replicas, desde una (en realidad no hay redundancia) hasta cinco copias. Obsérvese que hemos reconfigurado el objetivo 2 (espejo simple) para que una de las copias se almacene en un disco duro que esté etiquetado como HighCapacity [3]. Esta etiqueta no tiene contenido semántico para LizardFS, es una etiqueta que hemos puesto nosotros en los discos duros más grandes de esta instalación LizardFS. Es decir, estamos especificando tanto el nivel de redundancia como indicando información topológica. Con técnicas así se podría enseñar a LizardFS que evite ciertos discos duros o ciertos servidores si ya ha almacenado fragmentos en discos duros vecinos.
Otro objetivo configurado, que utilizamos para las pruebas, pero que ya no usamos, es el objetivo 8 o xor2h. Este objetivo divide un fichero en dos fragmentos y genera un fragmento nuevo de redundancia [1]. Teniendo acceso a dos de esos tres fragmentos, LizardFS podría reconstruir el fichero. Este formato permite perder un disco y recuperar la información teniendo una sobrecarga de solo el 50%, en vez del 100% que supone un espejo tradicional. Obsérvese que le estamos indicando también que queremos que al menos uno de los tres fragmentos se almacene en un disco duro etiquetado como HighCapacity [3].
El tercer objetivo que tenemos configurado es el 20 o ec82. Este objetivo genera dos fragmentos de redundancia a partir de ocho fragmentos de datos. Es capaz de recuperar los datos aunque hayamos perdido dos discos duros y su sobrecarga de espacio es de solo un 25%.
| [3] |
(1, 2) El objetivo en este caso no es tanto que se metan datos en los discos duros HighCapacity sino que se reserven los discos pequeños para poder asegurar los objetivos de redundancia. Los detalles son sutiles y tienen que ver con las características concretas de esta instalación LizardFS en particular. En concreto, disparidad extrema de los discos duros en cuanto a capacidad y rendimiento. Es interesante señalar que una configuración así impone también restricciones de capacidad para conseguir los objetivos de redundancia. Por ejemplo, en modo espejo, si tenemos un disco duro de 10 Terabytes etiquetado como HighCapacity, empleando nuestra configuración actual, estaríamos exigiendo a LizardFS que una de las copias se almacene en ese disco duro. La otra copia no puede estar en el mismo disco duro, así que tendrá que estar en otro diferente. Es evidente que la suma de la capacidad de todos los discos duros no etiquetados como HighCapacity no puede superar los 10 Terabytes del disco duro HighCapacity. Es decir, la capacidad total del almacenamiento no podría superar los 20 Terabytes, si queremos que LizardFS pueda cumplir los objetivos de redundancia que le exigimos para los ficheros en espejo. Ese límite de capacidad solo afecta a los ficheros configurados con un objetivo de espejo. Nótese que los ficheros configurados con un objetivo de ec82 no tienen restricciones sobre dónde dejar los fragmentos y, por tanto, no imponen límites al tamaño del almacenamiento. Ejemplo: supongamos que tenemos un disco duro HighCapacity de 10 TB y veinte discos duros de 1 TB. Solo podríamos grabar 10 TB de ficheros en espejo (una copia en el disco HighCapacity y otra fuera), pero podríamos tener 19.5 TB de ficheros en ec82. En este caso se usarían los veinte discos duros de 1 TB y 2 TB en el disco duro HighCapacity. Es más, ampliando el número de los discos duros pequeños, aumentamos la capacidad ec82 pero no la capacidad espejo, mientras no aumentemos el tamaño o el número de discos duros etiquetados como HighCapacity. Nota Posiblemente me he equivocado en los cálculos, pero espero que entiendas la idea. Con objetivos de redundancia avanzados es más facil recurrir a la simulación que intentar dar una respuesta analítica precisa. ¿Por qué entonces tenemos discos duros marcados como HighCapacity? El objetivo ec82 nos permite almacenar los fragmentos en cualquier sitio, pero necesita espacio en diez discos duros diferentes. LizardFS intenta equilibrar el espacio libre en los discos duros aun a costa de tener que migrar fragmentos de un disco duro a otro, pero es algo que es mejor evitar si tenemos una tasa de escritura elevada. En este caso es preferible obligar a que ciertos ficheros utilicen ciertos discos duros para asegurarnos de que los discos duros pequeños tienen espacio libre para acoger ec82 sin que LizardFS tenga que migrar cosas de un sitio a otro. Nótese que podríamos tener etiquetas marcando, por ejemplo, discos duros muy rápidos, y pedirle a LizardFS que almacene uno de los espejos de ciertos ficheros en esos discos duros ultrarápidos. Aunque la versión actual de LizardFS no permite expresar reglas elaboradas, no hay nada en la tecnología subyacente que lo impida. Un LizardFS futuro podría soportar reglas de redundancia arbitrariamente complejas. |